Commençons par le début
Oui, car ça fait un petit moment que je souhaite écrire une série d'articles sur Proxmox, articles présentant la mise en place de A à Z d'un cluster.
En effet, Proxmox depuis sa version 2 propose un système de clustering basé sur Red Hat, qui présente un potentiel très intéressant de fonctionnalités pour parvenir à un système très stable.
Accessoirement, ça présente également un potentiel de problèmes clairement non négligeables. Mais bon.
Dans cette série d'articles, je vais donc tâcher de présenter sous le biais de tutoriel, la mise en place d'un tel cluster. Cependant, comme il est difficile de couvrir tous les cas possibles, je vais me permettre de me placer dans un cas précis et défini, adaptable et qui correspond à une problématique assez difficile.
L'idée va être de configurer 3 serveurs distants géographiquement en cluster proxmox, avec un système de haute disponibilité.
Dans ce premier article, je vais donc présenter la problématique du système, ainsi que le vocabulaire et les concepts importants à comprendre et à retenir. Les prochains articles seront plus techniques, promis !
Néanmoins, je partirais du principe que vous avez déjà une petite expérience de Proxmox (au moins savoir l'installer !), et que vous maitrisez SSH tout en ayant des bases de réseaux. J'essaierai quand même de rendre le plus compréhensible possible les problématiques techniques !
Je m'excuse d'avance pour la longueur des articles, mais la réalisation est quand même assez complexe ;-)
Pour ces articles, je m'appuie principalement sur les 3 liens suivants (merci beaucoup à eux pour leur travail !)
- Blog du développeur neurasthénique; cluster proxmox via OpenVPN
- NedProduction : Configuring a Proxmox VE 2.x cluster running over an OpenVPN intranet (notamment la partie 3)
- Red Hat cluster tutorial (extrêmement complet si vous lisez l'anglais. Une mine !)
Je me suis également servi du forum et du wiki proxmox.
Vocabulaire
- Cluster : comme le dit wikipédia, un cluster est un ensemble de serveurs regroupés artificiellement ensemble pour permettre la gestion globale de ceux-ci, et éventuellement la mise en place d'un système de haute disponibilité.
- Node : une node est le nom donné à un serveur à l'intérieur d'un cluster. Un cluster est constitué de nodes, indépendantes ou non les unes des autres.
- Haute disponibilité : la haute disponibilité (High Availability, ou HA en anglais) consiste à assurer un service continu à vos utilisateurs/clients, même en cas de panne matérielle. Cela devient une vraie problématique dans les systèmes informatiques actuels, ou la simple indisponibilité pendant quelques heures d'un site web (le temps de changer un disque dur défectueux par exemple), peut rapidement se chiffrer en pertes financières importantes. La haute disponibilité permet donc de détecter automatiquement une panne et d'y réagir rapidement pour proposer une continuité de service. Cette continuité de service peut éventuellement être dépréciée, selon les standards recherchés. Par exemple le site web accessible, mais la plate-forme de paiement en ligne coupée temporairement.
- Plan de Reprise d'Activité : Le Plan de Reprise d'Activité (PRA) est la procédure mise en place justement pour permettre une continuité de service. Cette procédure doit donc permettre de remettre en route tout ou partie des services en cas de panne du service principal, dans un délai prévu d'avance. Le PRA doit faire l'objet de tests réguliers et être bien assimilé par tout le monde, notamment dans le cas où les services remontés en cas de panne sont dépréciés. Le PRA peut également être le nom donné affectueusement au(x) serveur(s) qui servent à remonter les services :-)
Sauvegardes : les sauvegardes consistent à garder une trace régulièrement des machines virtuelles ou des dossiers importants sur un serveur. Elles font en général partie intégrante d'un PRA, et elles doivent être gardées dans différents endroits physiques pour pallier à tout risque de perte en cas d'incendie ou autre problème grave. Attention, mettre en place un système de HA ne doit pas dispenser de faire des sauvegardes !- Quorum : le quorum est un concept assez difficile à appréhender, et pourtant il est absolument nécessaire à comprendre pour travailler sur un cluster en HA. Je vais donc m'arrêter un peu dessus pour expliquer le principe. D'après la page wikipédia, un quorum est le nombre minimal de personnes nécessaires pour prendre une décision dans un groupe. C'est un terme utilisé en droit habituellement, et un quorum représente en général la majorité, si tout le monde vote pour une voix. En informatique, le quorum est le nombre minimal de votes à atteindre pour prendre une décision automatiquement, comprendre sans intervention humaine.
Dans le cas d'un cluster, on peut donner à chaque serveur du cluster un poids différent ou identique, qui va influencer sur les choix que va prendre l'intelligence du cluster en cas de besoin. Par exemple, tous les serveurs ont un poids de un. S'il y a 5 serveurs, le quorum va être de 3. Il faut être au moins 3 pour prendre une décision. Dans ce cas, en cas de panne par exemple sur la liaison réseau entre les serveurs, ceux-ci prendront des décisions en fonction de leur quorum. Prenons un exemple :
Nous avons 5 serveurs, montés en HA, avec un poids de 1 chacun. Une panne réseau survient, qui isole 3 serveurs d'un côté et 2 de l'autre. Chaque serveur va vérifier la connectivité avec les autres. Les serveurs ayant le quorum (le groupe de 3), se trouvant en majorité, peuvent prendre la décision de démarrer chez eux les services précédemment hébergés chez les 2 serveurs manquants. Les serveurs n'ayant plus le quorum (le groupe de 2) vont par contre décider qu'ils ne sont plus en majorité, et donc déduire que d'autres ayant le quorum vont prendre leur place. Ils vont donc prendre la décision de couper leurs services, voire de s'éteindre en attendant une intervention extérieure.
Ce système permet d'éviter que des services tournent en même temps à deux endroits différents. Imaginez par exemple que la connexion entre les 2 groupes saute, mais que la connectivité Internet de chaque groupe fonctionne encore. Sans quorum, alors les utilisateurs seraient dirigés sur le site web de gauche ou de droite, rendant ingérable la restauration. En effet, si le site est un forum, alors les utilisateurs ont postés des messages à droite ET à gauche, il faudrait donc les fusionner pour revenir à un état stable sans perdre de données ! C'est un casse-tête qui a été réglé par la notion de Quorum.
Bien sûr, ce système n'est pas parfait. Pour reprendre notre exemple, si le problème de connectivité fait que nous avons deux groupes de 2 serveurs et un groupe de 1, aucun des groupes n'a le quorum et tous risquent de s'éteindre. De la même façon, si nous avons un nombre pair de serveurs (Par exemple 4), le quorum est exactement la moitié, ce qui fait qu'en cas de répartition égale des groupes de serveurs, chacun va décider de démarrer les services de l'autre groupe !
En conséquence, il est très important de bien comprendre cette notion. Dans l'idéal, vous devez toujours monter des clusters avec un nombre impair de serveurs, quitte à ce que l'un deux soit juste une machine virtuelle dans un coin servant 'd'arbitre'. Monter un cluster pair est possible, mais vous acceptez alors le risque de créer des situations qui seront difficilement gérables.
- Fencing : le fencing n'a pas vraiment d'équivalent en français. C'est une notion liée à la haute disponibilité de la même façon que le quorum, et qui sert principalement à éviter des situations où les services tournent sur deux parties du cluster indépendantes. Le fencing consiste à pouvoir isoler chaque node du cluster pour être sûr qu'elle ne reviendra pas inopinément.
Par exemple, si un serveur redémarre par accident, le cluster se voyant en majorité va démarrer les services de la node défaillante. Sauf que une fois la node redémarrée, elle va rentrer de nouveau dans le cluster, donc avoir la majorité, et donc décider de lancer ses services. Ce qui va provoquer de nouveau une situation de doublon.
Le rôle du fencing est donc d'autoriser le groupe du cluster ayant le quorum (ayant la majorité) à isoler artificiellement la ou les nodes défaillantes. Cela peut se faire en coupant le courant de la node (via un onduleur pilotable en réseau, via une carte DRAC ou ILO, ...), en coupant son réseau (via un switch manageable), en lui envoyant en boucle des ordres d'exctinction en ssh, ... Plusieurs techniques sont disponibles. Ce concept est important, et en général le plus compliqué et le plus lourd à mettre en place techniquement. Accepter de s'en passer peut poser un certains nombre de problème à l'administrateur, nous en parlerons plus loin. Dans Proxmox, le système de HA ne fonctionne pas si le fencing n'est pas configuré correctement.
Globalement, le quorum sert à pallier à une panne sur la liaison entre les machines, alors que le fencing sert à pallier à une panne matérielle de la machine. Ces deux concepts fonctionnent donc côte à côte.
- Fail-over : le principe du Fail-Over s'applique en majorité aux adresses IP publiques d'un serveur (parfois à son adresse MAC). Le principe d'IP fail-over est que dans le cas où un de vos serveurs tombe en panne, votre hébergeur est capable de router votre IP vers un nouveau serveur. Techniquement, chacun des serveurs est une copie de l'autre, et chacun des serveurs porte l'IP publique. Cependant, un seul des serveurs est joignable à un instant T, ce qui permet de manière bien pratique de ne pas avoir à changer tous les enregistrements DNS en cas de panne du serveur principal (les DNS pouvant mettre jusqu'à 48h à se rafraichir, on imagine bien qu'une telle technique est utile pour éviter que son site soit innacessible pendant 2 jours).
Voila pour le vocabulaire. Si d'autres mots vous posent problèmes durant la lecture d'un des articles, indiquez le dans les commentaires, je le rajouterai ici.
Problématique
Dans le cadre de la mise en place d'un cluster, le principe basique consiste à mettre plusieurs serveurs identiques dans une baie, et à se servir d'eux pour augmenter la disponibilité de ceux-ci.
Par exemple, vous avez 3 serveurs, si l'un d'eux tombe, vous basculez tous ses services quasiment instantanément sur les deux autres, vous permettant d'avoir une disponibilité des services continue, même en cas de panne matérielle.
De plus le cluster vous permet de gérer, depuis une seule interface, tous vos serveurs.
C'est ce que propose Proxmox V2. En montant différents serveurs en cluster, vous pouvez en vous connectant à l'interface web de n'importe quel serveur créer des machines virtuelles sur le serveur de votre choix, gérer les sauvegardes de manière globale, créer des droits d'accès, bref, faire tout ce qui est possible d'habitude, mais sur tous vos serveurs d'un coup !
En fait, la vraie problématique qui se pose est la suivante :
Quid si vous voulez également une redondance géographique ?
Là, ça devient plus compliqué. Se posent directement les problèmes de communication entre les serveurs (qui doit être sécurisée !), le temps de basculement en cas de panne (qui doit être réduit, sinon sans intérêt), la détection de panne, le basculement des IP publiques, la gestion des serveurs qui ne sont pas identiques, etc, etc.
Rare sont les hébergeurs (en fait, inexistant à moins de payer 3 bras par mois, et encore) qui proposent ce genre de service, à savoir notamment une communication cryptée et des serveurs identiques dans deux lieux géographiquement redondés. A la rigueur, dans deux salles différentes ça peut être possible, et vous leur déléguez tout l'aspect sécurité/redondance/basculement, en leur faisant confiance. (Voir cet article...)
Bon, la question ne se pose pas, je voulais tout faire moi-même, pour la gloire (et aussi pour mon porte monnaie, et également avoir une redondance de fournisseur, ça mange pas de pain).
Architecture
Mon système de serveur est assez simple. Je dispose d'un serveur principal, assez costaud, permettant de faire tourner la majorité des services. Certains de ces services sont importants et devront donc faire partie du HA. D'autres le sont moins et il est acceptable de s'en passer en cas de panne matérielle
En secours, je dispose également d'un deuxième serveur, chez un hébergeur différent, bien moins costaud mais à même de faire tourner les quelques services importants dans un mode déprécié.
Ces deux serveurs n'ont aucune liaison locale (étant chez deux hébergeurs différents), présentent des composants matériels différents (ils ne sont pas identiques) et dont donc placés à des endroits géographiquement différents, dans des réseaux différents. Ils ont également leurs propres IP publiques chez chacun des hébergeurs, rendant tout fail over impossible.
Chacun de ces serveurs utilise Proxmox comme système d'exploitation, et tous ces fameux services sont en fait placés dans des machines virtuelles, l'hyperviseur assurant un service minimum (en gros du routage et du NAT).
L'idée va donc consister à mettre en place un système de haute disponibilité pour les services souhaités, entre les deux serveurs, afin qu'une panne du serveur principal ne soit pas handicapante.
Quorum
Comme il est important de disposer d'un nombre impair de nodes pour permettre le fonctionnement du quorum, je rajoute à cette infrastructure un troisième serveur, qui n'héberge aucun service et sert uniquement d'arbitre. En fait, c'est une simple machine virtuelle avec Proxmox d'installé, hébergée chez moi.
Fencing
Malheureusement, peu d'hébergeurs proposent un système permettant la mise un place d'un fencing. Encore moins à travers Internet. J'ai donc du choisir de me passer de fencing. Ceci est un choix qui vous attirera les foudres de la communauté Proxmox/Red Hat, et qui risque de transformer toutes vos demandes sur les forums officiels en chasse à l'homme. J'en ai pleinement conscience. Cependant, la problématique technique imposée ne me laisse pas d'autres choix. Je proposerai donc dans ces articles un moyen de "tromper" le fencing pour permettre le bon fonctionnement du HA.
Il est important de comprendre que c'est un choix qui peut amener un certain nombres de problématiques techniques importantes, notamment pour remonter les services après une panne. Cependant, rien d'insurmontable. Mais c'est quand même très moche. Nécessité fait loi...
Multicast
Le système de cluster Proxmox nécessite une liaison multicast entre toutes les nodes. En effet, le cluster communique via ce biais entre les différentes nodes. Ce système présente l'avantage de supprimer la notion de maître/esclave présent dans Proxmox v1.X, mais est une problématique importante dans le sens qu'AUCUN réseau public n'autorise le multicast. Et surtout pas le réseau Internet.
Pour résoudre ce problème, j'utilise une liaison OpenVPN entre les nodes, et le cluster est construit via ce tunnel. Cela présente le double avantage de permettre facilement le Multicast sur Internet et de crypter la communication entre les nodes.
Cela présente le double inconvénient de remettre en place une notion de maitre/esclave (il faut un serveur VPN et des clients qui s'y connectent) et de rajouter un point de panne dans le système (si OpenVPN tombe, tout le cluster tombe). Nous verrons comment limiter ces deux problèmes.
Disque commun et réplication
Un autre point important dans un cluster HA est que les services HA doivent être répliqués. En effet, si vous voulez que votre serveur de secours puisse redémarrer les machines virtuelles en cas de panne du serveur principal, et bien il faut qu'il ait les données de ces machines à disposition. De plus dans un système HA, ces données doivent être temporellement les plus proches possibles entre le serveur principal et son serveur de secours, sinon vous risquez de perdre pas mal de données lors du démarrage du serveur de secours.
Comme il est couteux d'avoir à disposition un disque réseau supplémentaire à partager entre les serveurs (et qu'il est de plus impossible de le faire via Internet entre deux hébergeurs différents), j'ai fait le choix d'utiliser DRBD, un système permettant de mettre en place un RAID 1 via un réseau. Chaque action faite sur le disque du serveur principal est donc immédiatement répliquée sur le serveur de secours.
Ce système est plutôt robuste, mais est dépendant de la connexion entre vos serveurs. Plus votre liaison sera lente, plus le serveur de secours sera en retard par rapport au serveur principal, ce qui pose notamment problème dans le cas de base de données SQL. Cependant, la latence est minimale dans le cas d'hébergement proposant souvent au minimum 100Mo/s de bande passante.
Sachez tout de même qu'être trop grourmand sur le nombre de services répliqués peut entrainer des lenteurs sur vos machines virtuelles, le disque DRBD pouvant mettre en pause certains processus le temps d'écrire toutes ces données (Comme un disque classique d'ailleurs, bienvenue dans le monde des I/O Wait)
La synchronisation DRBD se fait via le tunnel Openvpn de la même façon que la communication inter-cluster.
Pour ma part, avec une base de données accessible à plusieurs dizaines d'utilisateurs plus une dizaine de serveurs écrivant leurs logs, je n'ai pas eu de soucis à ce niveau-là.
Edit : Attention, et c'est une contrainte importante, utiliser DRBD impose d'avoir des KVM comme uniques machines virtuelles HA. Je n'ai pas réussi à avoir de manière satisfaisante de l'OpenVZ sur du DRBD. Il reste possible d'utiliser OpenVZ pour toutes vos autres machines non HA.
Terminologie
Pour simplifier la suite, j'utiliserai les terminologies suivantes :
- Serveur principal : Serveur principal
- Serveur de secours : PRA
- Serveur "Arbitre" : Arbitre
- Haute Disponiblité : HA
Schéma
Parce que c'est toujours plus visible sur un bô schéma :)
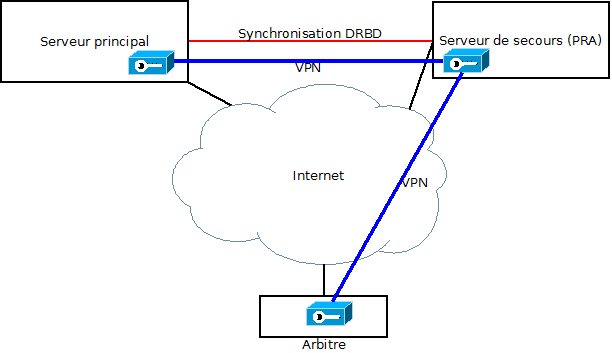
Le PRA fera serveur VPN principal, pour une raison simple : c'est lui qui est sensé tourner en permanence.
- Si le serveur principal tombe, l'arbitre sera connecté en VPN sur le serveur de secours, qui aura donc le quorum immédiatement et pourra lancer le mode de secours
- Si l'arbitre tombe, le serveur principal aura le quorum (étant connecté au PRA), les services tourneront donc normalement
- Si le PRA tombe, le serveur principal devient serveur VPN secondaire. Le système de backup OpenVPN fait que l'arbitre revient se connecter sur lui plutôt rapidement. Le serveur principal retrouve donc le quorum rapidement et les services tournent normalement
Bon, on commence quand ?
Et bien voila, je crois avoir fait le tour de présentation du système que je vais vous apprendre à monter.
Les tutoriels suivants expliqueront comment mettre en place le cluster via OpenVPN, comment monter la réplication DRBD et comment mettre en place le HA en lui-même.
Normalement, tout cela devrait tenir en 4 articles.
Si vous avez des questions sur ce concept ou avez besoin de détails, n'hésitez pas à me laisser un commentaire !
EDIT : un petit sommaire pour avoir une idée de ce que devrait parler les prochaines articles
- 1/4 : Le concept, que vous venez de lire
- 2/4 : Construction du cluster (openvpn), où on parlera installation, OpenVPN, personnalisation des serveurs et sécurité
- 3/4 : Réplication disque (DRBD), où on parlera de l'installation de DRBD et des diverses configurations qui en découlent
- 4/4 : Haute Disponibilité (HA), où on parlera de la configuration du HA, sa mise en place, sa gestion et l'ajout de VM à l'intérieur (fencing, cluster.conf, ...)
A bientôt :-)

Comments
Si vous avez des questions, si quelque chose n'est pas clair, n'hésitez pas à commenter !
tranxene50
Posted on
Hello !
Ouh punaise... J'attends la suite (technique) avec impatience !
Je crois que je n'ai jamais lu un article aussi didactique (en français) et notamment en ce qui concerne la notion de quorum avec Proxmox.
Pour le fencing, c'est clair qu'une solution matérielle est a privilégier mais il est possible (me semble-t-il) de tricher avec un "fence device" virtuel (à creuser, cela implique quelques sacrifices).
Au niveau de DRBD, même si cela fonctionne correctement, je pense qu'il va y avoir un souci avec les applications qui utilisent massivement la mémoire (cache/buffer), par exemple MySQL.
Ce que je veux dire c'est que, répliquer les fichiers Innodb ne suffit pas pour garantir l'intégrité des bases : si le serveur de secours démarre, il y aura forcément un recovery des BDD. (A tester dans la vie réelle, MySQL se démerde plutôt bien dans ce cas de figure).
De tout ce que j'ai lire, pour migrer des containers OpenVZ sans aucune perte de données, il faut impérativement sauvegarder l'état de la mémoire (checkpointing).
Concernant les IP fail over, quand on utilise des serveurs dédiés via des prestataires différent, c'est clairement la plaie (marche pas...).
Je cherche toujours une solution a ce problème mais, de ce que j'ai pu comprendre, il faudrait passer un prestataire tiers qui reroute le trafic (donc c'est du transit) là où il faut. Le souci c'est qu'on utilise leur bande passante (logique) et donc, il facturent cela.
A+
Victor
Posted on
Hello !
Merci, j'essaye d'être précis :)
Pour tes questions, je vais tâcher de traiter ces sujets dans la suite. Mais rapidement, ce que je peux en dire :
- Le fencing peut être détourné via Node Assassin (qui peut faire du fencing via SSH) ou du Manual Fencing (qui consiste à attendre une intervention humaine se chargeant du fencing, donc aucun intérêt). Node Assassin est assez intéressant, mais dans l'optique où la connexion entre les 2 machines est mortes (ce qui est le cas le plus répandu dans un contexte distant comme ça), ça ne sert à rien et le PRA tourne en boucle en attendant de réussir son fencing. La solution la plus simple (et moche !) consiste à bidouiller un script qui retourne exit 0 après avoir envoyé un courriel d'alerte...
- DRBD va imposer (j'aurai peut être pu en parler là d'ailleurs, désolé) d'utiliser KVM. J'ai passé de longues semaines à tenter de faire fonctionner OpenVZ sur DRBD, mais à travers un lien Internet, la latence est trop importante, et le système d'OpenVZ fonctionnant avec des dossiers (private, root, ...) n'est pas viable. Peut être avec le futur ploop, mais alors on perd tout l'intérêt d'openvz-diff-backup :) Etre sous KVM est donc une contrainte importante en effet. Mais ça fonctionne correctement, même avec Mysql, dans le sens où DRBD a une notion de cohérence des données plutôt bien foutue. Pour ma part, je n'ai pas eu de soucis lors de mes tests à ce niveau là.
- Pour les IP failover, je "règle" le problème avec une passerelle portant l'IP publique sur chaque système, qui n'est pas en HA. Et cette passerelle met un jour les DNS dynamiques automatiquement en cas de besoin. C'est le moyen le plus propre que j'ai pu trouver. (Voir l'article sur le DynDNS OVH) Pas vraiment du failover, mais la vitesse de réplication est acceptable (environ 10 minutes), ça marche parfaitement avec des liens IPsec par exemple.
Jérôme
Posted on
Bonjour,
Alors, on commence quand ? :)
Je suis actuellement en train de réfléchir à mettre en place une solution basé sur Proxmox HA/DRBD mais non pas entre différents hébergeurs sur une ligne à forte latence mais en LAN.
Je risque d'avoir au moins autant de problèmes que vous étant donné que je n'ai encore aucunes solutions pour tromper le fencing et que le projet partait avec 2 noeuds dans le cluster et non 3.
Je vous remercie pour les détails que vous avez apporté notamment sur les notions de quorum et de fencing pas très simple à comprendre à la première approche.
En ce qui me concerne, la solution me servira à mettre des serveurs M$ SQL donc des machines KVM synchronisés via DRBD mais comme le fait remarquer tranxene50 et à juste titre, il risque d'y avoir quelques / nombreuses incohérences dans les données.... Vous faites d'ailleurs remarqué que vous n'avez pas eu de soucis lors de vos tests, faisiez vous des nombreuses requêtes sur le serveur SQL avant de le copier et de couper subitement le serveur principal ?
Ceci étant dit, j'attend la suite avec impatience, la pub commence à se faire longue :)
Bonne journée à vous Bien cordialement
Victor
Posted on
Hello,
En fait, j'ai des brouillons en cours, mais je prend pas mal de temps à retester chaque chose que j'écris et à essayer que ça ne soit pas trop abstrait, donc ça me prend un peu de temps. (Et de motivation) Ceci dit, vu qu'effectivement ça a l'air d'intéresser, ça va me pousser un peu en avant (ça fait jamais de mal ^^)
J'espère pouvoir sortir la série d'ici la fin février, mais ça dépends de mon temps libre donc c'est toujours sujet à caution...
Pour ce qui est du reste, mes tests se sont fait en Mysql sur une BDD de quelques Go. Ce n'est pas une base SQL en frontend pour un site de plusieurs milliers d'utilisateur, donc elle n'est pas intensément utilisée, mais ceci dit j'ai effectivement fait des tests en coupant les machines et en les redémarrant, ça ne m'a pas posé de problème.
Ceci dit le problème est plus conceptuel. En pratique, vu que la HA prend le secours d'une machine en panne, la machine principale s'est en général fait couper "mochement", et donc s'il y avait du SQL en cache, il est perdu. La machine en HA redémarre complètement (ce n'est pas une live migration ou un resume), donc la base SQL lance ses patch correctifs s'il y a lieu. En tout cas, c'est ce que j'ai constaté avec Mysql, je ne connais pas assez SQL server.
Si vous êtes en LAN, je ne saurais trop vous conseiller de trouver un moyen de faire du fencing matériel. Si vous avez la main sur le matériel, un onduleur manageable est très envisageable. Ceci dit, j'ai eu à faire face à ces contraintes donc je ne vous jetterai pas la pierre :)
Par contre, 3 noeuds restent conseillés pour bien gérer le HA. Ceci dit, le wiki proxmox a été mis à jour assez récemment pour supporter un disque de quorum (en fait, juste un petit disque ISCSI servant d'arbitre), c'est un concept qui peut être intéressant dans votre cas en LAN (Sur Internet, OpenVPN est nécessaire) : Quorum disk Proxmox
A plush'
Gégé
Posted on
Bonjour,
j'ai trouvé votre article très intéressant et assez précis pour répondre à pas mal de questions sur le cluster HA de Proxmox.
Je suis moi-même en train de monter un cluster à trois noeuds avec HA et je retrouve dans votre article quelques réponses à mon questionnement.
J'en ai pourtant encore quelques unes (des questions) qui n'ont pas encore trouvé de réponse.
exemple: dans un cluster ha proxmox quelle doit être l'attitude des noeuds valides lorsqu'un troisième noeuds à perdu le contact (perte alimentation par exemple) . Dan mon cas lors de la perte totale d'un noeud il ne se passe rien jusqu'au retour du noeud arrêté . Les VM configurées avec HA et présentes sur ce noeud migrent à ce moment là. Je ne pense pas que ce soit un fonctionnement normal.
J' ajoute que mes test de fencing (notamment avec l'outil fence_node ou en debranchant le reseau d'un des noeuds) ont donnés des résultats satisfaisant.
si vous avez un petit moment de libre à consacrer a ce problème, je vous en serais très reconnaissant .
merci d'avance
cordialement
Victor
Posted on
Bonjour Gégé,
Effectivement, ce n'est pas un comportement normal. Normalement, dès que le 3eme serveur disparait, toutes les machines en HA devraient migrer quasi-instantanément vers les serveurs de secours.
Pour trouver ce qui cloche, il faudrait regarder ce qui se passe dans les logs. Normalement, le syslog (/var/log/syslog) donne pas mal d'informations sur le fonctionnement du cluster. Dès qu'un serveur disparait, ça apparait dans les logs sous la forme d'une dizaine de lignes expliquant la nouvelle configuration (qui est parti, qui est resté, état du quorum, etc). De plus, un des serveur restant est élu aléatoirement pour s'occuper du fencing. Le résultat du fencing est également écrit dans les logs.
Il faut savoir que le cluster est freezé tant que le fencing n'est pas réussit, c'est à dire qu'aucune machine en HA ne migrera si le fencing échoue. Dans le fonctionnement, le serveur élu pour effectuer le fencing va essayer toutes les méthodes qui ont été définies dans le cluster.conf pour la machine en panne. Si elles échouent toutes, il va les réessayer, et ainsi de suite jusqu'à ce qu'une des méthodes réussissent.
Il est possible que lorsque tu déconnectes ton 3eme serveur, le système qui te sert de fencing se déconnecte aussi ? Auquel cas, il est possible que le fencing n'arrive jamais à se faire et du coup les machines en HA ne migrent pas. Et dès que le serveur revient, le fencing aussi, donc il réussit et les machines migrent.
Il y a également une sécurité lorsque leHA est activé, qui fait qu'une machine qui est sorti du quorum et qui revient va automatiquement être exclue des décisions tant qu'elle n'aura pas été redémarré proprement. (En fait, le cluster "tue" le gestionnaire clvm du serveur fautif, cela apparait dans les log sous la forme "clvm killed by node X")
Il est aussi possible de définir des priorité, des temps de migration, etc pour chaque machine dans le cluster.conf, peut être as-tu un problème à ce niveau là ?
Pour en savoir plus, tu peux essayer de regarder l'état du cluster lorsqu'un de tes serveurs est tombé, à l'aide des commandes suivantes :
Voila, c'est tout ce que je peux dire avec ces éléments.
Bon courage !
A plush'
Victor
Gégé
Posted on
Bonjour et merci pour ta réponse.
j'ai réitéré la manip .
le pvecm n me met bien le node arrété en status X
le pvecm s prend bien en compte que 2 nodes avec un quorum de 2
le clustat m'indique bien que le node arrété est "Offline" le rgmanager est bien arrété le service qui concerne la VM (pvevm:100) me donne le dernier possesseur mais son état est "started"
en ce qui concerne le syslog il y a une erreur dans le fencing du node arrété ( peut-être que mon fencing n'est pas tout a fait OK, ou peut être est ce normal).
je me permet de t'envoyer le partie du syslog intéressante . J'espère ne pas trop abuser de ton temps .
En tous cas merci pour tout.
A bientôt
Gégé
Gégé
Posted on
Oups!
ça ira mieux si j'envoie le fichier.
encore merci
GG
Victor
Posted on
Hello,
Si tu veux, je t'invite à mettre ton adresse courriel dans tes commentaires, elle ne sera visible que par moi, et ça sera plus pratique pour discuter :)
(En attendant que je répare mon formulaire de contact ^^")
Pour ce qui est des logs, il semble bien que c'est le fencing qui pose problème.
la machine-proxmox1 (qui est node 2 si je lis bien) disparait, et donc machine-proxmox2 essaye le fencing.
On voit bien qu'il échoue en boucle, dans ce cas là, aucun service HA ne se lancera. En effet, le cluster considère qu'il ne peut pas être sûr que la node est vraiment "morte", et donc que peut être les VM tournent encore dessus. Pour éviter des corruptions sur le disque de données synchronisé (DRBD, NFS, SAN, ...), le cluster ne peut pas relancer les VM en HA tant qu'il n'est pas sûr que l'hôte est down.
Après, si ton fencing marche quand tu débranches des câbles, et pas en cas de coupure de courant, il faudrait peut être brancher ta carte ILO sur une alimentation séparée ? Voir avec un onduleur séparé ?
Est ce que en lançant un fencing à la main avec le fence_agent ça fonctionne bien ? Même si le courant est coupé ?
En tout cas, ton problème semble venir de là :)
Bon courage
A plush'
Victor
Gégé
Posted on
Hello aussi,
j'ai desalimenté un node ,puis j'ai tenté le fencing de ce node en essayant:
fence_node machine-proxmox1 mais j'ai un retour failed
quand je l'execute machine allumée c'est OK.
Ah Dur! Dur! le fencing
je sens que j'y suis presque mais il me manque toujours un petit truc pour valider un HA digne de ce nom
en tout cas merci pour ton aide
Gégé
Jérôme
Posted on
Bonsoir,
Veuillez s'il vous plait continuez à régler le problème par commentaire, ça m'intéresse beaucoup. En effet je suis aussi en train de mettre Proxmox en place en environnement de test pour le moment seulement je ne dispose pas encore de suffisamment de serveurs pour tester le fencing en fonctionnement réel. J'utilise le mode "human" qui indique que c'est aux admins de s'occuper du fencing.
Utilisant DRBD pour synchroniser le disque, j'ai une petite question. Est-ce qu'on doit utiliser (dans mon cas /var/lib/vz) le mode master-slave ou master-master ? Car la aussi, si on utilise DRBD en master-slave il doit y avoir des options de fencing pour que le noeud slave prenne la main sur la ressource n'est-ce pas ? Ca m'arrangerait bien que vous validiez mes dires :)
Victor vous avez l'air vraiment documenté sur le sujet. Les commentaires sont vraiment constructifs.
Merci à vous pour cette mine d'informations!
Bien cordialement
Victor
Posted on
Hello,
Désolé, c'est vrai que je pense que les commentaires ne sont pas un support très appropriés pour une discussion technique de ce type. Les courriels sont plus pratiques, et permettent plus d'espace de discussion. Surtout que j'ai tendance à être très verbeux ^^
Pour l'instant, la discussion avec Gégé semble porter sur un problème de fencing. Le système marche bien en cas de coupure réseau ou de tests manuels, mais le fencing n'est plus efficace lors d'une coupure de courant. En effet l'interface permettant le fencing n'est plus alimentée non plus, et donc impossible de s'en servir.
Du coup les nodes encore allumées tentent en boucle de fencer la node morte, sans succès.
Dans ce genre de cas, les machines en HA ne sont jamais relancées, puisque tout les services cluster sont bloqués même si les nodes ont le quorum. Une solution est alors effectivement de configurer un fencing 'human' pour pallier ce défaut, mais du coup adieu l'automatisme. Pour gégé, il faut essayer de trouver une solution avec une alimentation de secours, voire un onduleur permettant de donner le temps au fencing d'agir :)
Pour ton problème de DRBD, et dans le cas particulier de Proxmox, il est bien plus simple de mettre en place un disque master/master. ATTENTION ! Il faut que le disque ne soit utilisé que d'un côté à la fois ! Typiquement, prévoir un disque DRBD pour les machines de la node A, et un disque DRBD pour les machines de la node B. En master/master, dès l'activation du HA les machines basculées ont les droits d'écriture et peuvent démarrer. Mais il est impératif que toutes les machines tournant sur le disque DRBD basculent d'un coup. Si certaines tournent à gauche et d'autres à droite, ça peut poser de gros problèmes. (Split brain, comme on dit)
Dans tous les cas et dans le cadre de ce tuto, le basculement est prévu pour être automatique, mais pour remonter le cluster, il faudra y aller à la main, principalement pour cette raison : il faut dire à DRBD quelle node possède les bonnes données et quelle node doit voir ses données écrasées par une synchro.
Dans le cas où tu n'utilises pas l'ISO Proxmox, et tout particulièrement si tu n'utilises pas LVM pour ta partition système/ton swap, il est possible dans le cluster.conf de définir des "failover domains" qui gèrent les ressources, donc DRBD et LVM. Dans ce cas, tu peux activer le mode master sur un disque DRBD en cas de déclenchement de HA, et tu peux également utiliser CLVM (Clustered LVM), une extension de LVM qui permet de gérer la synchronisation sur DRBD de manière très sympathique (notamment la gestion de qui a le droti d'écrire à quel moment, et qui a raison). Cependant, utiliser ces techniques demandent que LVM soient lancé par les processus de cluster uniquement une fois que les nodes ont démarrées, ce qui est impossible dans le cas de l'ISO Proxmox, puisque la partition système est sur LVM.
Cette technique de CLVM semble permettre plus facilement l'utilisation d'OpenVZ sur DRBD également.
J'ai choisi dans ces tutos d'utiliser l'ISO Proxmox car son partitionnement LVM se prête bien à la gestion des disques DRBD. Je n'utilise donc pas CLVM, et mes disques DRBD sont en master/master, ce qui pose au final relativement peu de problèmes, étant prévu pour fonctionner en mode Serveur principal/Serveur de secours (Aucune VM ne tournant donc sur le disque DRBD du serveur de secours)
Voila, j'espère avoir pu vous aider :)
Jérôme
Posted on
Bonjour,
Le problème de Gégé m'interpelle, admettons qu'on dispose d'un cluster Proxmox en HA (principal, secondaire, arbitre) avec une partition logique DRBD repliquée entre le serveur principal et secondaire. La solution est basé sur du fencing au niveau node, carte de management uniquement.
Si un des noeuds est coupé électriquement, l'arbitre et le secondaire s'arrange pour "fencer" le noeud principal via sa carte de management qui n'est plus alimentée et donc... va attendre indéfiniment qu'il revienne dans le cluster pour le killer ? ...
Les deux serveurs secondaire et arbitre n'auront donc jamais démarré les services du principal ?
Y'a bon ou je suis vraiment à côté ? :)
Victor
Posted on
Hello,
Je confirme, c'est effectivement le cas. Si le système de fencing est en rade, et que du coup le fencing échoue en boucle sur l'arbitre et/ou le serveur de secours, alors les services en HA ne démarreront jamais.
Et en plus dès que le serveur principal se fera de nouveau alimenté, il sera fencé direct.
C'est pourquoi il est conseillé par Proxmox (et Red Hat) d'avoir plusieurs systèmes de fencing pour gérer tous les types de pannes.
En l'occurrence, je pense qu'il est possible d'alimenter indépendamment une carte iDrac ou ILO ? (je ne connais pas bien ce matériel)
Pour ma part, j'ai remplacé un script de fencing (le script de node assassin) par un script envoyant un courriel et se terminant par exit 0 pour que la node ait l'impression de réussir le fencing. Surement pas la solution idéale, mais à distance... Enfin j'en ai déjà parlé :)
A plush'
Jérôme
Posted on
Bonjour,
Je re-confirme, après en avoir discuté avec d'autres personnes sur freenode.org, il m'a été dit que ce genre de pannes n'était pas pris en charge, il est donc vivement conseillé de disposer d'un système de fencing au niveau node de type PDU, onduleur manageable plutôt que des cartes de management, ou du moins, en plus du fencing avec les cartes.
Je commence de plus en plus à me demander, comment le HA de VMware fonctionne. Il s'agit d'environ 80% du parc de virtualisation qui est fournit par VMware, est-ce que le fencing est-il aussi abordé qu'avec Proxmox ?
Je ne sais pas si c'est de vous, ou de quelqu'un d'autre mais il me semble avoir entendu que les noeuds se suicident dans les systèmes HA de VMware, en savez-vous davantage? Et si oui, quel est votre point de vue entre ces deux types de fencing ?
Pour ma part, ce problème d'alimentation des cartes de management n'est pas en soi un problème étant donné que c'est aux administrateurs d'intervenir sur les systèmes pour promouvoir un master pour DRBD, activer les volumes LVM et démarrer la VM mais c'est des notions très intéressantes qui montrent combien le fencing peut être contraignants (selon le point de vue de chacun :)) et combien le HA de Proxmox ne se permet pas de créer des situations de split brain.
Voyez, moi aussi je suis très verbeux :)
Bien cordialement Jérôme
Victor
Posted on
Hello,
Ah, je ne pense pas que cette affirmation sur VMWare vienne de moi. Là, je dois bien admettre mon manque (total ? :s) de connaissance sur VMWare.
Je n'ai encore jamais eu l'occasion d'y toucher, sans parler du temps. Ceci dit, c'est effectivement intéressant de confronter les fonctionnements vis à vis du HA, qui est un système critique mais en même temps extrêmement difficile à gérer.
A ce sujet là Proxmox est très limitatif, et autant ça peut parfois être bloquant, autant c'est un fonctionnement qui peut se comprendre. Après, si on l'outrepasse, il faut également être conscient des risques ;) Et puis sur ce genre de principe de cluster en HA, il y aura toujours (toujours !) des cas qu'on n'aura pas pu tester, ou auxquels on n'aura même pas pensé...
Des noeuds qui se suicident sont une solution intéressante, mais c'est quand même étrange, comment font-ils sans alimentation (par exemple) ? Et comment les nodes restantes peuvent-elles être sûres que c'est le cas ? Ou alors, en partant du fait que sans le quorum, la node DOIT se suicider, alors les nodes restantes sont sûres que c'est bien le cas, et si jamais elle n'a pas pu le faire (alimentation, encore) c'est qu'elle n'est de toute façon plus en état de fournir le service. Pourquoi pas en effet, c'est une vision inverse de Proxmox mais qui a ses arguments :)
Merci de m'avoir signalé ça tiens !
A plush'
Jérôme
Posted on
Bonjour :)
Oui, la notion peut paraître déroutante... Si ce n'est pas de vous, c'est en dévorant des blogs ou des sites qui parlent de libre où j'ai du voir ça... Il me semble que c'était soufflé sans affirmation, aucunes.
Dans le principe, le noeud ne peut plus transmettre au cluster (pas de réponses au multicast par exemple), il ping la passerelle, s'il n'obtient pas de réponses, alors il désactive ses services du cluster en se disant que les autres noeuds du cluster vont activer les services qu'il proposait auparavant... Il se suicide via un reboot, une extinction, je ne sais pas vraiment... en ce qui concerne un problème réseau par exemple...
En ce qui concerne une panne d'alimentation... Le cluster fonctionne normalement, un des noeuds vient à sortir du cluster (il ne répond plus à ses pairs), ses services sont donc considéré comme éteint/libre par le cluster et il va alors s'arranger pour les démarrer sur les noeuds restants....
Voilà.. voilà.. mais encore une fois, ce n'est là en aucune manière une affirmation du fonctionnement du HA de VMware... Enfin, les hypothèses sont vraiment intéressante. Il serait sympa de pouvoir choisir dans les modes de fonctionnement du HA de Proxmox, afin de pouvoir coller avec toutes les situations... ;)
A proposer dans la roadmap ;)
Bien cordialement
Jérôme
Ozzi
Posted on
Bonjour,
Tout d'abord merci pour votre explication très claire des notions de quorum et de fencing et pour votre article en général !
Vous dites qu'utiliser drbd avec openVZ n'est pas réalisable, est-ce vraiment le cas ? Je suis actuellement le tuto de nedProduction que vous citez au début de l'article et il me semble que toutes ses VM sont en openVZ lorsqu'il met en place drbd.
D'ailleurs pensez vous bientôt publier votre 3ème article dans lequel vous aborderez drbd ? :)
Victor
Posted on
Hello,
C'est vrai que je n'ai pas précisé en détail le problème d'OpenVZ avec DRBD. En fait, le principal souci est que via DRBD, on gère un système de fichier, et que du côté d'OpenVZ, on gère une arborescence de fichier. Du coup, autant DRBD marche très bien avec KVM (qui est un disque virtuel, pour lesquels DRBD peut utiliser un système d'état de cohérence), autant il a du mal avec l'arborescence OpenVZ. De plus, OpenVZ utilise un dossier "private" où il stocke les fichiers de la VM, et un 2eme dossier "root" où il place les fichiers de la VM quand elle fonctionne, mais qui n'existe plus quand elle est arrêtée, etc.
Et ça, d'expérience DRBD n'aime pas du tout, car il se lance dans des réplications dans tous les sens quand une VM démarre, et ensuite a du mal à retrouver un état de cohérence de disque.
J'ai fait des tests en utilisant un système de fichier lvm fait exprès pour gérer ce genre de souci avec LVM (clvm), mais le problème est que clvm doit être lancé au démarrage de LVM, et comme Proxmox utilise LVM pour ses propres partitions, CLVM se lançait dès le démarrage, c'est à dire avant que DRBD n'ai pu établir sa connexion, ce qui crashait complètement le système (à éviter donc !) C'est une technique qui fonctionnerait sans doute sur une machine sans LVM pour ses partitions (peut être une debian classique avec Proxmox par dessus), mais je n'ai pas été plus loin, Proxmox étant à utiliser pour moi :)
Ce problème pourrait également être réglé avec le nouveau système de fichiers en projet d'OpenVZ, ploop, qui consisterait à utiliser comme KVM un genre de disque virtuel plutôt que directement l'arborescence de fichiers, mais ça pose d'autres soucis (notamment que c'est quand même super pratique pour les backups et les manip' cette arborescence ^^)
Plus précisément pour le tuto de NedProduction, il utilise DRBD uniquement dans un sens, c'est à dire plus à vue de backup. Son deuxième disque ne peut en aucun cas servir à faire redémarrer une machine en étant monté sur le système de secours. Dans un système HA, il faut que les deux côtés du disque puissent être utilisées en écriture par le système (mode "primary" dans DRBD), et donc il s'agit de faire très attention à ce que le PRA n'écrivent rien dessus tant que le serveur principal est encore là (sinon, fort risque de conflit, écriture sur les même secteurs disques, etc, et là, tout plante). NedProduction n'a pas cette problématique et donc ses machines OpenVZ se synchronisent tranquillement sur son deuxième serveur uniquement en lecture, fichier par fichier. Ceci dit, peut être que quelque chose m'a échappé, mais j'ai testé sa configuration, dans une problématique de HA ce n'est pas viable (l'option de synchronisation "C" de DRBD interdit que les deux côté du disque puissent être en écriture)
Pour ce qui est du 3eme article, je suis toujours sur le brouillon, mais ces derniers mois ont été chargés niveau boulot, je n'ai pas eu tout le temps que j'aurai voulu pour me remettre sur les configurations et les tests du tuto... Cependant je ne l'oublie pas !
Voila, j'espère que le problème est un peu plus clair après cette (longue :s) explication. Et merci pour votre lecture :)
A plush'
Ozzi
Posted on
Bonjour !
Oui le problème est beaucoup plus clair maintenant, merci pour l'explication :)
C'est très embêtant pour moi car nous n'avons que des container OpenVZ et qu'on me demande de mettre en place de la HA... Mais on trouvera une solution !
Bonne continuation pour vos tutos en tout cas ;)
Ozzi
Posted on
Bonjour,
Je continue mes tests pour avoir de la HA pour mes containers OpenVZ. J'utilise ipmi pour le fencing, et lorsque j'utilise fence_node j'ai toujours success comme résultat. Si je stoppe un host avec le bouton power, la migration de machine se fait automatiquement et correctement. Cependant, si je débranche le cable réseau ou le cable d'alim, le fencing échoue en boucle, comme pour Gégé. C'est pourquoi je reviens vers vous, avez vous résolu son problème ? Pensez-vous qu'il est possible d'avoir du fencing correct en utilisant seulement ipmi ?
Merci d'avance pour vos réponses
Victor
Posted on
Hello,
Je pense que le souci vient de là effectivement. En ipmi, dès que la machine est coupée du monte (pb réseau ou courant coupé), elle ne peut être joignable, et du coup les serveurs de secours doivent échouer en boucle à lancer le fencing.
Du coup, ils ne prennent pas la responsabilité de lancer les machines en HA.
A mon avis, en utilisant uniquement ipmi, le fencing ne sera pas 100% fonctionnel pour cette raison. Il faudrait peut être rajouter une deuxième option de fencing (qui sera lancée automatiquement si ipmi échoue) et qui appelle un script qui renvoi toujours le status 0 (c'est à dire fencing réussi). C'est malheureusement la seule solution que j'ai pu trouver pour ma part en l'absence de matériel dédié au fencing, même si elle n'est pas très propre. Tant qu'à faire d'ailleurs, mieux vaut inclure dans ce script un envoi de courriel automatique, comme ça tu seras prévenu rapidement s'il se trouve qu'il est appelé :)
Bon courage
Victor
Arnaud
Posted on
Bonjour,
Merci beaucoup pour ton article t ;)
Cependant j'ai quelque question . Pourquoi à ton besoin de LVM ? pour les snapshot ?
Et pour NFS, il y a un intérêt ou pas ?
Merci pour vos futurs réponses.
Victor
Posted on
Hello,
Désolé pour la latence dans la réponse :s
LVM être très intéressant pour utiliser DRBD derrière.
D'abord parce qu'il va permettre de redimensionner et de libérer facilement de la place pour le disque DRBD (et de laisser de la souplesse si plus tard tu as besoin de changer ces espaces disques).
Ensuite parce que DRBD aime bien LVM en ce sens qu'il peut utiliser les snapshot pour faire des "points de cohérence". C'est à dire que lors de la synchronisation des disques DRBD entre-eux, il utilise l'espace libre LVM pour optimiser la synchronisation afin que les données soient toujours au maximum cohérentes :)
Pour NFS, je ne sais pas trop si LVM apporte un réel intérêt, à part encore la possibilité d'être souple sur le dimensionnement des partitions et des disques (Enfin ça, c'est l'avantage inhérent à LVM :) )
J'espère avoir répondu à ta question.
A plush'
Damien
Posted on
Bonjour!
Merci pour le tuto qui est très bien rédigé!
je suis entrain de construire un projet de test via: vmware workstation. j'aurais voulu tester la HA de proxmox. le seul problème c'est comment fencer une vm via vmware? ou alors tromper le fencing, pour lui faire croire que c'est bon.
j'ai pour l'instant 3 node proxmox + 2 drbd avec server nfs en cluster(en actif/passif), qui tourne sur workstation 9.
si vous avez une petite idée?
merci!
Victor
Posted on
Hello Damien,
Désolé, je ne connais pas du tout vmware.
A l'instinct, je te dirais de chercher si via ton hyperviseur vmware tu peux envoyer des signaux de simulation type "extinction physique de la machine virtuelle" pour faire croire à proxmox que c'est bon la node est bien éteinte.
Une façon universelle de le tromper sinon, ça peut être de permettre aux nodes de se connecter sur ton vmware en ssh/telnet/ipmi, et de faire sur le vmware un script appelé par le fencing qui couperait la node demandée :
- La node 1 est en défaut
- La node 2 demande le fencing, elle contacte l'hyperviseur en lui demandant de couper la node 1
- L'hyperviseur effectue un shutdown de la node 1
- L'hyperviseur répond par le biais sur script qu'il a correctement coupé la node 1 (code de retour 0)
Ca devrait suffire à faire croire au HA que le fencing a fonctionné.
Pour la réalisation technique par contre, ça dépendra beaucoup de comment une node peut comuniquer avec l'hyperviseur, je n'en sais pas plus :s
Ca reste du bidouillage, en production je te conseille quand même du proxmox sur des machines physiques :)
Bon courage.
A plush'
matthieu
Posted on
Bonjour,
Merci pour cet article intéressant.
J'ai une interrogation que j'aimerai confirmer auprès de vous:
Le fencing est utile uniquement dans le cas où, le serveur hôte ne répond plus sur son interface de management (système figé), mais que les VM continu de fonctionner. Dans ce cas, pour éviter d'avoir deux hyperviseurs qui accède au stockage partagé le fencing rentre en action pour tuer l'hôte planté.
Mais sérieusement, dans combien de cas cette situation arrive ?
Corrigez moi si je dis une bêtise, mais de mon point de vue, dans 90% des cas, le mécanisme quorum doit suffire. Je m'explique, notre hôte principale se trouve isolé du réseau suite à une panne d'un switch.
Dans ce cas, le fencing de l'autre neoud ne peut rien y faire et tourne en boucle, mais le serveur va automatiquement détecter qu'il a perdu le quorum et stopper automatiquement les ressources HA.
J'aimerai bien avoir un retour sur combien de personne se sont trouvé dans des situations ou le fencing a été plus utile que le quorum.
Merci
Victor
Posted on
Bonjour Matthieu,
Je suis tout à fait d'accord, le fencing est plutôt rarement utile, et souvent même une source d'ennui.
Cependant, les 10% de cas où il s'avère utile (hyperviseur planté mais VM continuant de tourner), il est absolument nécessaire car 2 machines qui écrivent au même instant sur un disque, c'est le plantage définitif assuré, avec peu d'espoir de réparer.
Du coup, restauration de sauvegardes, remise en route, tout ça tout ça. A condition d'avoir bien géré ces parties bien sûr :)
Du coup, même si le fencing est parfois compliqué à gérer (notamment sur des clusters distant), il est absolument nécessaire. Au début, je pensais aussi que c'était vraiment une perte de temps pour pas grand chose, j'ai mis un peu d'eau dans mon vin depuis après avoir rencontré quelque cas d'écritures concurrentes comme dis au dessus.
Il est parfois préférable que le cluster décide de ne pas remettre en route les machines s'il ne peut pas être sûr qu'elles sont effectivement coupées, et envoie un message à l'administrateur pour le prévenir de son indécision, plutôt qu'il prenne une décision catastrophique au niveau des machines.
En nombre de cas, le fencing est sans doute "peu" utile. Par contre comparativement à la difficulté de régler un cas où il n'a pas fonctionné, je pense que ça vaut le coup de s'y pencher quand même.
Voila pour mon avis, j'espère qu'il aura été constructif :)
belou
Posted on
euh, un an après, tu n'arrive plus à ecrirer l suite, je hate de voire le technique pour tromper fence device
Pier
Posted on
Bonjour,
Merci pour cet article (je ne l'ai pas encore terminé), j'ai une suggestion pour la traduction de fencing (ca me permet également de vérifier que j'ai bien compris le concept), on pourrait traduire fencing par "cloisonnement" , non ?
Victor
Posted on
Bonjour Pier,
Question intéressante pour la traduction, je ne suis pas fan de "cloisonnement" dans le sens ou tu ne cloisonne pas vraiment le serveur (tu ne l'empêche pas vraiment de fonctionner), mais plutot tu t'assures qu'il soit vraiment coupé.
Ca peut être effectivement en coupant son réseau (donc en le cloisonnant), mais aussi en lui coupant l'alimentation, en lui disant "sors du cluster", etc
A ce titre il faut avouer que c'est un mot qui prête un peu à confusion.
(mais il est vrai que la traduction littérale de fence en français correct serait clôture)
Simon
Posted on
Article vraiment génial !! J'éspère que cela donnera envie a certain de passer a proxmox !
Le petit vocablaire en début d'article est assez utile, de plus nous n'avons p-e pas tous les mêmes conception de certains termes.
A +